
Bio

Queenie Luo is a Ph.D. candidate in Religion / Philosophy at the Department of East Asian Languages and Civilizations at Harvard University, and has concurrently completed a Master of Science in Data Science from the School of Engineering and Applied Sciences at Harvard.
Queenie led the Norbu Ketaka project to clean 1,000,000 pages of Classical Tibetan manuscripts using Natural Language Processing and Computer Vision methods, and donated the database to the Buddhist Database Resource Center (BDRC) upon completion. Queenie also works at the Institute for Quantitative Social Science (IQSS) on the China Biographical Database project (CBDB), where she developed the Lepton and Kraft models, which have successfully assisted CBDB in expanding its database repository by employing AI techniques.
Before joining the Ph.D. program at Harvard, Queenie completed her M.T.S in Buddhist Studies at Harvard Divinity School and graduated summa cum laude from Columbia University with a B.A. in Religion and Physics. Before coming to Columbia, Queenie immersed herself in the Fashion Industry. At age nineteen, she became the youngest fashion designer to have a couture collection showcased at Vancouver Fashion Week and went on spend three years studying Fashion Design at Parsons School of Design in New York. In 2018, Queenie received the Phi Beta Kappa Prize, which is awarded to the candidate who best represents the ideals of the society—intellectual integrity, tolerance for other views, and a broad range of academic interests. Her current research at Harvard focuses on algorithmic bias, AI ethics, and applying machine learning techniques to East Asian studies.
Articles
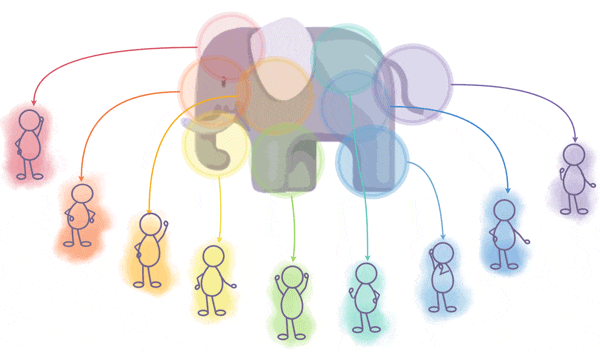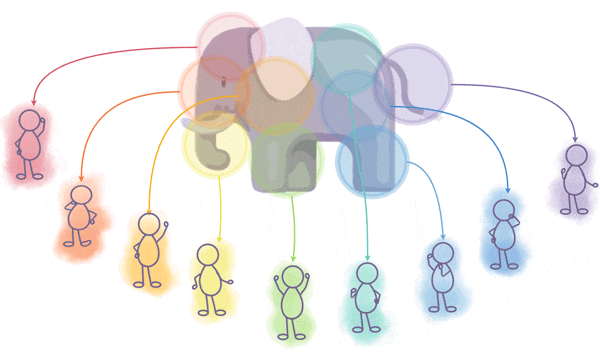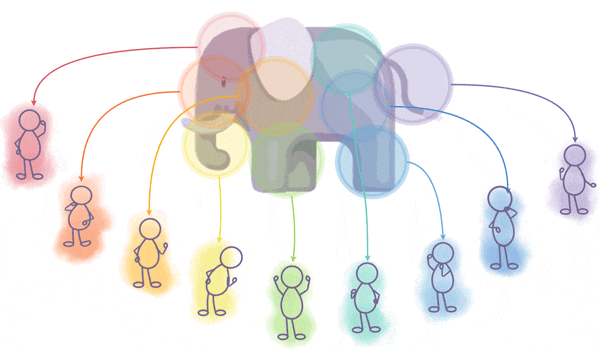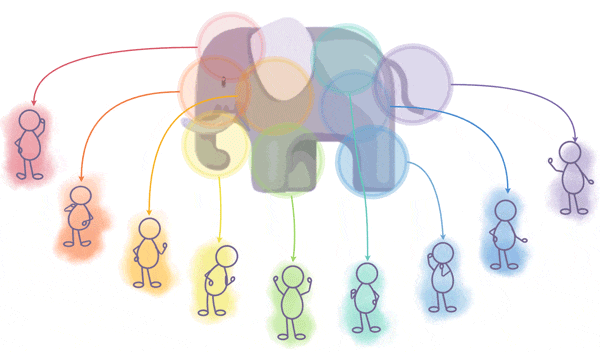
[1] Queenie Luo, Michael J. Puett, Michael D. Smith. “A Perspectival Mirror of the Elephant: Investigating Language Bias on Google, ChatGPT, Wikipedia, and YouTube”. ACM Queue, 22, 1. January/February 2024
Press: Wikimedia Research Newsletter, Twitter
[2] Queenie Luo†, Yung‑Sung Chuang† “Cleansing Jewel: A Neural Spelling Correction Model Built On Google OCR‑ed Tibetan Manuscripts”. ACM Transactions on Asian and Low-Resource Language Information Processing. Just Accepted (April 2024). († indicates equal contribution.)

[3] Queenie Luo, Leonard W. J. van der Kuijp. “Norbu Ketaka: Auto-Correcting BDRC’s E-Text Corpora Using Natural Language Processing and Computer Vision Methods”. (Forthcoming from Tibetan digital humanities and natural language processing. PIATS 2022: Proceedings of the Sixteenth Seminar of the International Association for Tibetan Studies.)
Press/Related Link: Norbu Ketaka database , BUDA
Projects

Norbu Ketaka Database
Project lead: Queenie Luo, Principal Investigator: Leonard W. J. van der Kuijp.
Description: The Norbu Ketaka project employs the latest cutting-edge technologies in AI and deep learning to process one million pages of Tibetan texts. This includes the labeling of training data, adjustments to neural network architectures, and the creation of new Natural Language Processing (NLP) and Computer Vision models. Additionally, a personnel management system was designed and implemented using the Google Docs API and Google Drive API, which facilitated the distribution of 12,000 documents to 40 part-time annotators based on their Tibetan proficiency and time availability, as well as tracking and evaluating the quality of the edited documents. The final “cleaned” texts are donated to BDRC and publicly accessible here.
Press/Related Link: Norbu Ketaka database, BUDA

Kraft
Authors: Queenie Luo, Yafei Chen, Hongsu Wang, Kanghun Ahn, Sun Joo Kim, Peter Bol, CBDB Group
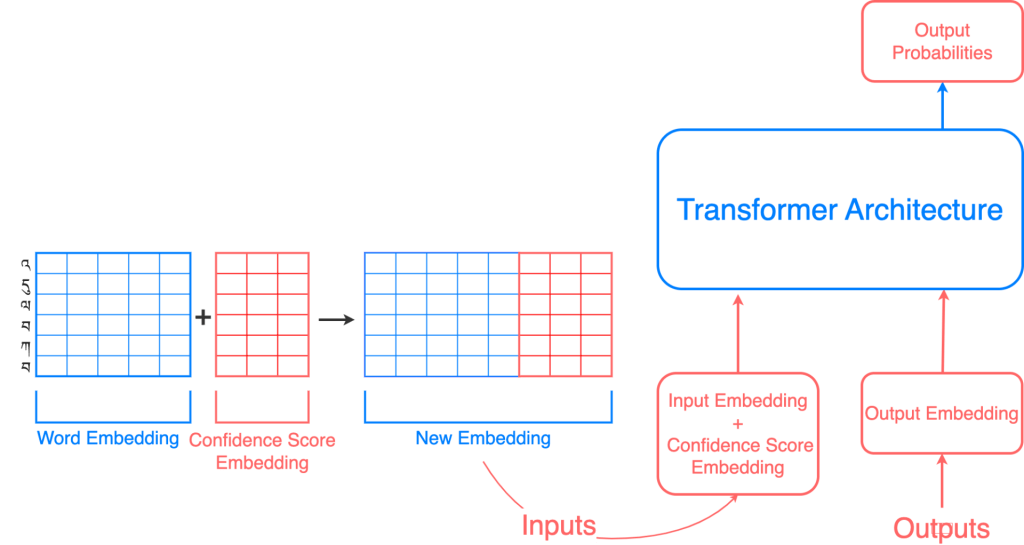
Description: The Kraft (Korean Romanization From Transformer) model translates the characters (Hangul) of a Korean person-name into the Roman alphabet (McCune–Reischauer system). Kraft uses the Transformer architecture, which is a type of neural network architecture that was introduced in the 2017 paper “Attention Is All You Need” by Google researchers. It is designed for sequence-to-sequence tasks, such as machine translation, language modeling, and summarization.
Code: Hugging Face Kraft Model
Lepton
Authors: Queenie Luo, Katherine Enright, Hongsu Wang, Peter Bol, CBDB Group
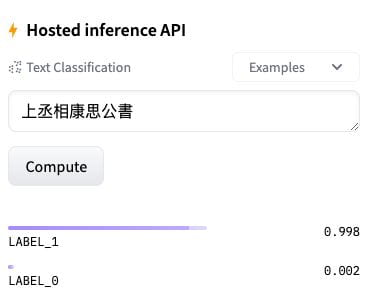
Description: The LEPTON (Classical Chinese Letter Prediction) model is BertForSequenceClassification Classical Chinese model that is intended to predict whether a Classical Chinese sentence is a letter title (书信标题) or not. This model is first inherited from the BERT base Chinese model (MLM), and finetuned using a large corpus of Classical Chinese language (3GB textual dataset), then concatenated with the BertForSequenceClassification architecture to perform a binary classification task. (Labels: 0 = non-letter, 1 = letter) This model helped CBDB efficiently and accurately identify 50,000 letters and build a letter platform for Ming letter association research.





























